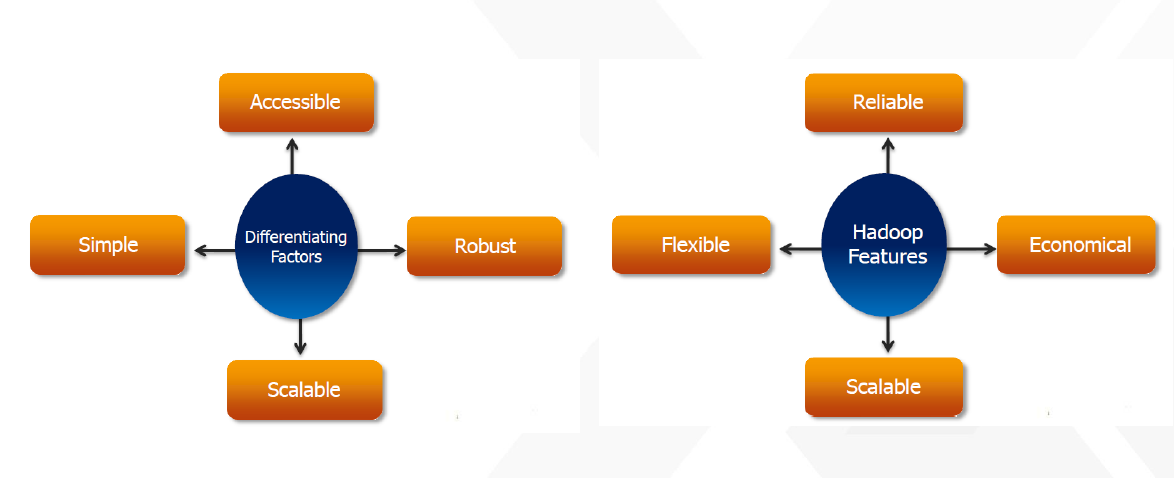
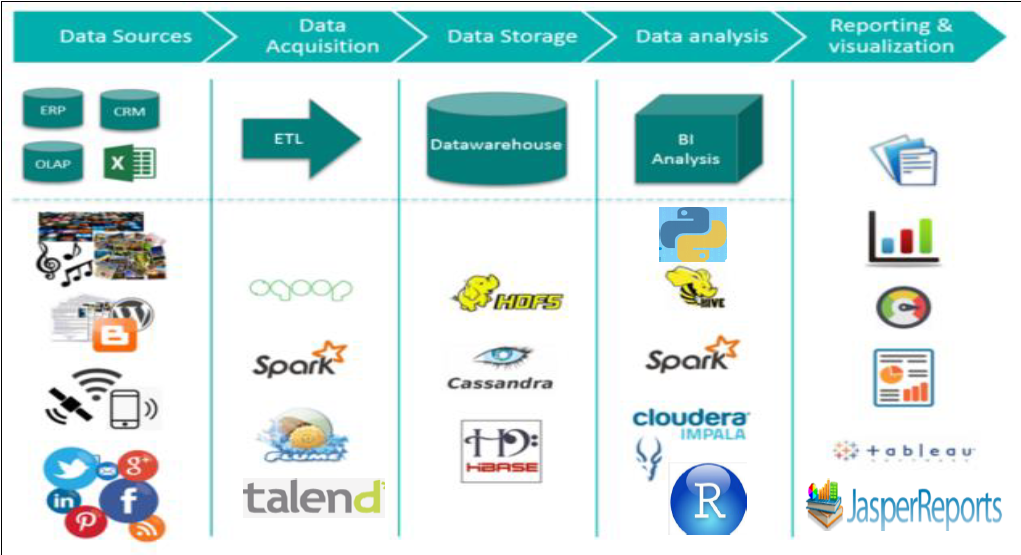
Apache Hadoop-2.7.0- Components
- The Apache™ Hadoop® project develops open-source software for reliable, scalable, distributed computing.
- The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models.
- It is designed to scale up from single servers to thousands of machines, each offering local computation and storage. Rather than rely on hardware to deliver high-availability, the library itself is designed to detect and handle failures at the application layer, so delivering a highly-available service on top of a cluster of computers, each of which may be prone to failures.
>The project includes these modules:
• Hadoop Common: The common utilities that support the other Hadoop modules.
• Hadoop Distributed File System (HDFS): a distributed file-system that stores data on commodity machines, providing
very high aggregate bandwidth across the cluster.
• Hadoop YARN: a resource-management platform responsible for managing computing resources in clusters and using
them for scheduling of users’ applications.
• Hadoop MapReduce: A YARN-based system for parallel processing of large data sets(programming model for large
scale data processing)
There are five pillars to Hadoop that make it enterprise ready:
1. Data Management: Apache Hadoop YARN, HDFS
2. Data Access: Apache Hive, Apache Pig, MapReduce, Apache Spark, Apache Storm,Apache Hbase, Apache Tez, Apache Kafka, Apache Hcatalog, Apache Slider, Apache Solr, Apache Mahout, Apache Accumulo
3. Data Governance and Integration: Apache Falcon, Apache Flume, Apache Sqoop
4. Security: Apache Knox, Apache Ranger
5. Operations: Apache Ambari, Apache Oozie, Apache ZooKeeper
Providers
Commercial Vendors:
- Cloudera
- Hortonworks
- IBM Infosphere Biginsights
- MapR Technologies
- Think Big Analytics
- Amazon Web Services (Cloud based)
- Microsoft Azure (Cloud based)
Open Source Vendors
- Apache
- Apache Bigtop
- Cascading
- Cloudspace
- Datameer
- Data Mine Lab
- Data Salt
- Data Stax
- Data Torrent
- Debian
- Emblocsoft
- Hstreaming
- Impetus
- Pentaho
- Talend
- Jaspersoft
- Karmasphere
- Apache Mahoot
- Nutch
- NGData
- Pervasive Software
- Pivotal
- Sematext International
- Syncsort
- Tresata
- Wandisco
- Etc..