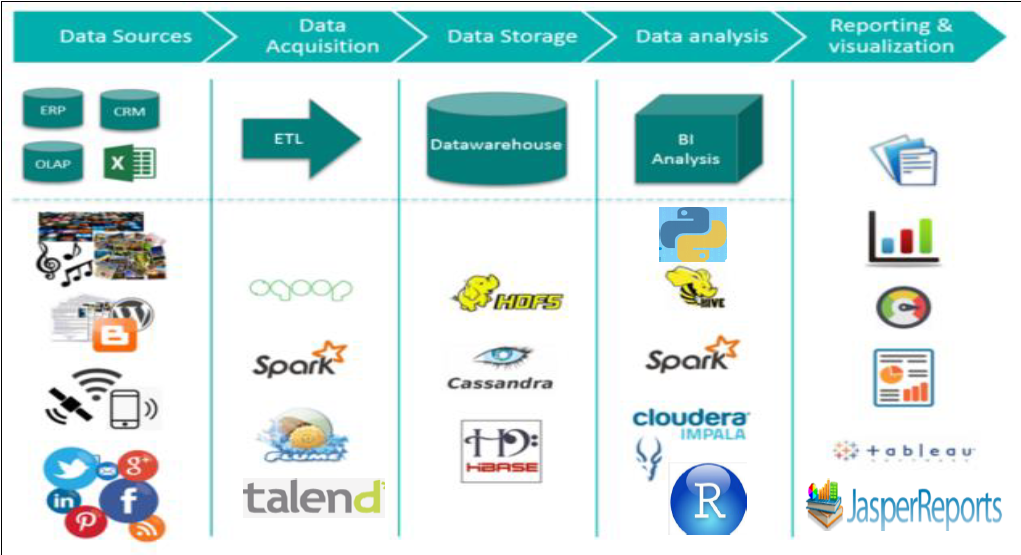
Q1- What is the role of a Data Architect in an organization?
Answer: A Data Architect plays a critical role in designing and implementing the organization's data infrastructure. They are responsible for creating data models, defining data storage and integration strategies, ensuring data quality and security, and enabling efficient data access and analysis. Additionally, they collaborate with stakeholders to understand business requirements and translate them into scalable and performant data solutions.
Q2-What are the key components of a data architecture?
Answer: A data architecture typically comprises several key components:
Data sources: These are the systems, databases, applications, and external sources from which data is collected.
Data storage: It involves selecting appropriate technologies and structures for storing structured and unstructured data, such as data lakes, data warehouses, or relational databases.
Data integration: This involves designing mechanisms to efficiently ingest and integrate data from various sources into a unified view.
Data processing: It includes designing data pipelines, transformations, and data processing frameworks for data enrichment and analysis.
Data governance: It encompasses defining policies, standards, and procedures for data management, data quality, metadata, and security.
Data access and visualization: This component focuses on enabling data discovery, access, and visualization for business users through tools and interfaces.
Q3-What are some best practices for data modeling?
Answer: Data modeling is crucial for structuring and organizing data effectively. Here are some best practices:
Understand business requirements: Work closely with stakeholders to gather requirements and align data models with business needs.
Choose the right modeling technique: Depending on the use case, select an appropriate modeling technique like entity-relationship (ER) modeling, dimensional modeling, or graph modeling.
Normalize and denormalize data: Normalize data to eliminate redundancy and ensure data integrity. Denormalize data where performance and query optimization are critical.
Establish naming conventions and standards: Define consistent naming conventions for entities, attributes, and relationships to ensure clarity and maintainability.
Use appropriate data types: Select appropriate data types that accurately represent the data and optimize storage and processing efficiency.
Document and maintain models: Document models thoroughly and keep them up to date as the data landscape evolves.
How do you ensure data quality in a data architecture?
Answer: Ensuring data quality is essential for reliable data analysis. Here are some approaches:
Data profiling: Perform data profiling to understand data patterns, anomalies, and data quality issues.
Data cleansing: Implement data cleansing processes to correct data errors, remove duplicates, and standardize data formats.
Data validation: Apply data validation rules and checks during data ingestion and transformation to ensure data accuracy and integrity.
Data lineage tracking: Establish data lineage to track the origin, transformation, and movement of data to ensure its traceability and reliability.
Data quality monitoring: Continuously monitor data quality through automated checks, exception reporting, and proactive data quality metrics.
Data governance: Implement data governance practices to enforce data quality standards, define data ownership, and establish data stewardship roles.
Q4-How do you approach data security in a data architecture?
Answer: Data security is a critical aspect of a data architecture. Here's an approach to ensure data security:
Access controls: Implement role-based access controls (RBAC) and fine-grained permissions to restrict data access based on user roles and responsibilities.
Encryption: Employ encryption techniques to protect data at rest and in transit. Utilize encryption algorithms and key management practices provided by the cloud platform or industry standards.
Data masking and anonymization: Mask or anonymize sensitive data to protect individual privacy and comply with data protection regulations.
Audit and monitoring: Implement logging and monitoring mechanisms to track data access, changes, and potential security breaches. Regularly review audit logs for suspicious activities.
Security policies: Define and enforce security policies, including password policies, data classification, and data retention policies.
Regular security assessments: Conduct periodic security assessments, vulnerability scans, and penetration testing to identify and address potential security risks.
Q5-What is real-time data processing, and how is it different from batch processing?
Answer: Real-time data processing refers to the ability to process and analyze data as it arrives, providing immediate insights and responses. It allows for instantaneous decision-making and actions based on up-to-date information. In contrast, batch processing involves processing data in large volumes at scheduled intervals. Real-time processing is characterized by low latency, near-instantaneous processing, and continuous data ingestion, while batch processing is suitable for large-scale data analysis but may have higher latency.
Q6-How do you design a real-time data processing architecture?
Answer: Designing a real-time data processing architecture involves several components:
Data ingestion: Implement mechanisms to collect and ingest data in real-time, such as using event-driven architectures or streaming platforms like Apache Kafka.
Data processing: Utilize scalable and fault-tolerant frameworks like Apache Spark or Apache Flink to process incoming data streams, perform transformations, enrichments, aggregations, and computations.
Message queues and event-driven systems: Use technologies like RabbitMQ or Apache Pulsar to handle high-throughput data streams and ensure reliable message delivery.
Real-time analytics: Integrate tools like Apache Druid or Elasticsearch to enable real-time analytics and querying of the processed data.
Visualization and alerts: Connect the processed data to visualization tools or alerting systems to provide real-time insights and notifications for business stakeholders.
Q7-How do you ensure data consistency and reliability in a real-time data processing system?
Answer: Ensuring data consistency and reliability in real-time data processing systems involves the following measures:
Idempotent processing: Design processing logic to be idempotent, meaning that processing the same data multiple times has the same result, ensuring data consistency in case of retries or failures.
Data validation: Implement data validation checks during ingestion and processing stages to identify and handle data quality issues or anomalies.
Error handling and fault tolerance: Employ fault-tolerant processing frameworks that can handle failures gracefully and provide mechanisms like automatic retries or error queues for processing failures.
Data replication and backup: Replicate and backup critical data to prevent data loss in case of failures.
Monitoring and alerts: Implement robust monitoring and alerting systems to detect and respond to issues promptly, ensuring data reliability and system uptime.
Q8-How do you address scalability challenges in real-time data processing?
Answer: Scalability is crucial in real-time data processing to handle increasing data volumes and growing user demands. Some approaches to address scalability challenges include:
Distributed processing: Utilize distributed processing frameworks like Apache Spark or Apache Flink that can scale horizontally across a cluster of machines to handle large data workloads.
Data partitioning: Implement data partitioning techniques to distribute data across multiple processing nodes, enabling parallel processing and minimizing bottlenecks.
Auto-scaling: Leverage cloud platforms that offer auto-scaling capabilities, allowing the system to dynamically provision or deprovision resources based on workload demands.
Microservices architecture: Adopt a microservices architecture to decompose the system into smaller, independently scalable services, each responsible for specific processing tasks.
Caching and in-memory computing: Utilize in-memory caching techniques to store frequently accessed data, reducing the need for repeated computations and improving overall system performance.
Q9-How do you ensure low-latency processing in a real-time data architecture?
Answer: Achieving low-latency processing in a real-time data architecture involves the following strategies:
Use efficient data serialization formats: Choose compact and efficient serialization formats like Apache Avro or Protocol Buffers to minimize data transmission and processing overhead.
Streamline data transformations: Optimize data transformation and processing logic to minimize computational complexity and reduce latency.
Data partitioning and parallel processing: Implement data partitioning techniques and parallel processing frameworks to distribute the workload across multiple processing nodes, enabling faster data processing.
Utilize in-memory caching: Leverage in-memory caching technologies to store intermediate results or frequently accessed data, reducing disk I/O and improving processing speed.
Optimize network and infrastructure: Ensure high-speed network connectivity and utilize high-performance infrastructure to minimize network latency and processing delays.
Good luck with your interview!